




【数据可视化】中国足球数据可视化

中国足球数据可视化
一、确定主题
在各大洲,我们都可以看到足球的影子。它为世人所喜爱,是一项名副其实的国际性运动。2004年初,国际足联宣布:“足球最早起源于中国古代的蹴鞠。”中国国家足球队始创于1924年,它承载着中国亿万球迷的热爱,支持和期望,但中国足球在近现代的表现确实有点不尽人意。迄今为止中国男足仅杀入过02日韩世界杯,小组赛惨遭淘汰,这也让中国球员及中国球迷意识到中国队与世界强队之间存在着巨大差距,中国国家足球队虽然成绩不大理想,可是毕竟是我国国家队,球迷们一有国足的比赛还是会为它高声呐喊加油助威的,下面让我们通过数据来进一步了解国足
北京时间5月30日19:30,世界杯亚洲区预选赛第二轮,中国在苏州奥体中心对阵关岛,武磊领衔,蒋光太和吴兴涵上演首秀。上半场,中国队始终保持着控球,武磊制造点球并亲自主罚命中,随后又头球中柱,艾克森造险,金敬道和吴曦精彩配合,攻入自己的处子球;下半场,中国队转换进攻思路,武磊梅开二度,吴曦门前嗅觉灵敏完成破门,艾克森头球继续扩大领先优势,阿兰虽然屡次错过好机会但也在最后时刻撞射破门并在随后完成梅开二度,最终中国7-0大胜关岛。
二、数据获取
来自FIFA国际足联,和网上公开资源自我整合
三、数据可视化
1.国足世界排名数据可视化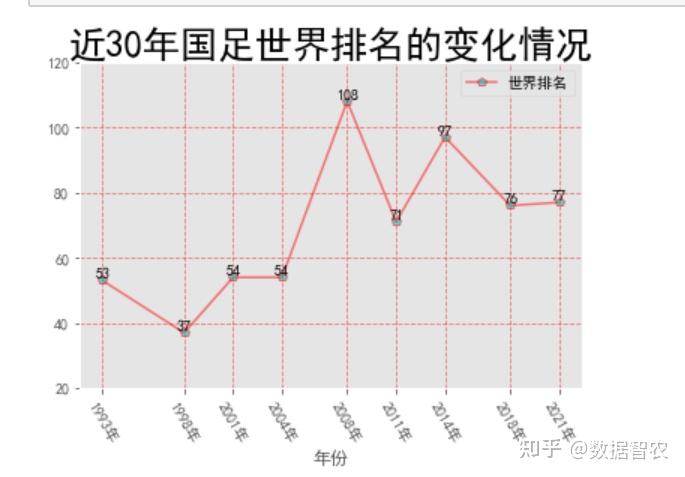
代码:
#导库
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#导入数据
pd.set_option('display.unicode.east_asian_width',True)#解决数据输出时列名不对齐的问题
df=pd.read_excel(r"C:\Users\11488\Desktop\1.xlsx",sheet_name="Sheet1")
x=df['year']
y=df['placing']
#解决中文乱码问题
plt.rcParams['font.sans-serif']=['SimHei']
#解决符号不显示问题
plt.rcParams['axes.unicode_minus']=False
plt.plot(x,y,color="r",marker="p",linestyle="-",alpha=0.5,mfc="c")#添加曲线格式
plt.xlabel("年份")
plt.ylabel("排名")
#设置坐标轴范围
dfdate=['%s年' % i for i in df["year"]] #设置标签内容
plt.xticks(x,dfdate,rotation=300)#将X轴上的x位置赋值上x标签
plt.ylim(20,120)#将Y轴的坐标轴范围设定为0-5000
plt.grid(color="r",linestyle="--",alpha=0.5) #设置网格线,如果想隐藏哪个轴的网格线,就使用axis=x或者axis=y去隐藏.
for x,y in zip(x,y):plt.text(x,y+2,'%d'%y , ha='center',va='center',fontsize=10)
plt.title("近30年国足排名变化",fontdict={'fontsize':25,'fontweight':20,'va':'center'},loc="center")#添加图表标题
plt.legend(("排名",))#添加图例
plt.show()
2.球员能力数据: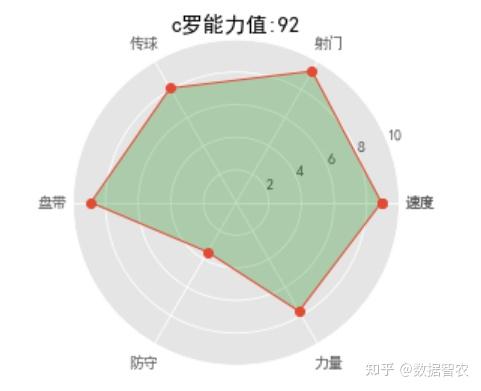
代码:
import numpy as np
import matplotlib.pyplot as plt
# 用于正常显示中文
plt.rcParams['font.sans-serif'] = 'SimHei'
#用于正常显示符号
plt.rcParams['axes.unicode_minus']=False
# 使用ggplot的绘图风格,这个类似于美化了,可以通过plt.style.available查看可选值,你会发现其它的风格真的丑。。。
plt.style.use('ggplot')
# 构造数据
values = [8.9,9.3,8.1,8.9,3.5,7.7]
feature = ['速度','射门','传球','盘带','防守','力量']
# 设置每个数据点的显示位置,在雷达图上用角度表示
angles=np.linspace(0, 2*np.pi,len(values), endpoint=False)
# 拼接数据首尾,使图形中线条封闭
values=np.concatenate((values,[values[0]]))
angles=np.concatenate((angles,[angles[0]]))
feature=np.concatenate((feature,[feature[0]]))
# 绘图
fig=plt.figure()
# 设置为极坐标格式
ax = fig.add_subplot(111, polar=True)
# 绘制折线图
ax.plot(angles, values, 'o-', linewidth=1)
# 填充颜色
ax.fill(angles, values,facecolor='g',alpha=0.25)
# 设置图标上的角度划分刻度,为每个数据点处添加标签
ax.set_thetagrids(angles * 180/np.pi, feature)
# 设置雷达图的范围
ax.set_ylim(0,10)
# 添加标题
plt.title('c罗能力值:92')
# 添加网格线
ax.grid(True)
plt.show()
3.中国足球真实情况
中国足球差,很多人会说“泱泱大国,14亿人里,找不出11个会踢球的人吗?”但由图中可以很直观的看出,中国虽然总人口多,但踢球的人口基数少,比例与日韩及欧洲国家相比简直没法比,因此才造成了中国足球差,冲不出亚洲走不出世界。中国注册职业球员相比其他足球强国相差甚远,数据看上去似乎有些夸张,但这就是中国足球存在的问题,也是中国足球急需改变的,球员的基数小,好球员自然也少。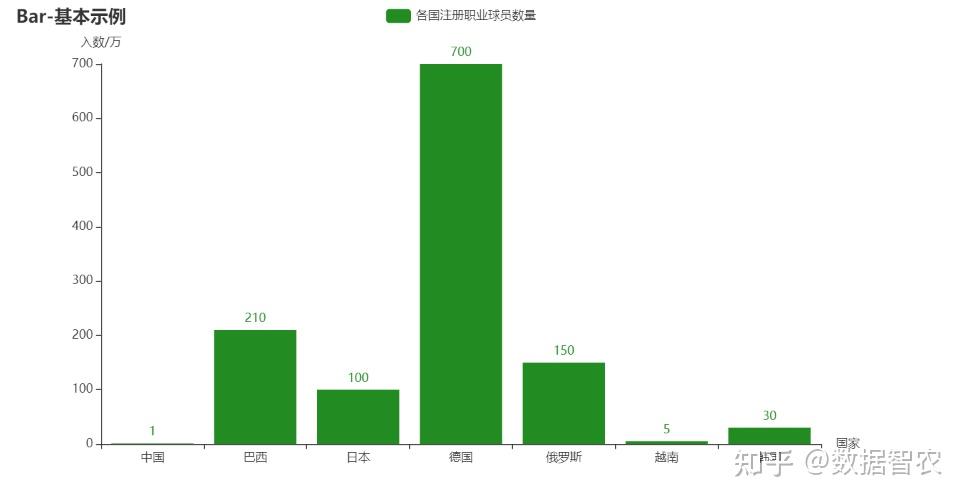
代码:
from pyecharts import options as opts
from pyecharts.charts import Bar
l1=['中国','巴西','日本','德国','俄罗斯','越南','韩国']
l2=[1,210,100,700,150,5,30]
bar = (
Bar()
.add_xaxis(l1)
.add_yaxis("各国注册职业球员数量", l2,color='#228B22')
.set_global_opts(
title_opts=opts.TitleOpts(title="Bar-基本示例"),
yaxis_opts=opts.AxisOpts(name="入数/万"),
xaxis_opts=opts.AxisOpts(name="国家"),)
)
bar.render_notebook()
4.中国足球发展及未来
改革开放以来,我国经济社会快速发展,人民生活水平显著 提高,群众对体育健身需求日益增长。当前,我国正处于全面建 成小康社会的关键时期,振兴和发展足球是全国人民的热切期 盼,关系到群众身心健康和优秀文化培育,对于建设体育强国、 促进经济社会发展、实现中华民族伟大复兴的中国梦具有重要意 义。发展和振兴足球,是建设体育强国的必然要求,也是人民群众的热切期盼。为进一步推动落实《中国足球改革发展总体方案》(以下简称《总体方案》),解决足球事业发展当前的主要困难和问题,中国足协研究制定了《进一步推进足球改革发展的若干措施》
中超球队分布如下
代码:
from pyecharts import options as opts
del list
data=pd.read_excel(r"C:\Users\11488\Desktop\2.xlsx",sheet_name="Sheet1")
province=list(data["province"])
gdp = list(data["yield"])
list=[list(z) for z in zip(province,gdp)]
list
c = (
Map(init_opts=opts.InitOpts(width="1000px", height="600px")) #可切换主题
.set_global_opts(
title_opts=opts.TitleOpts(title="2021年各省职业足球队数量分布图 单位:个"),
visualmap_opts=opts.VisualMapOpts(
min_=0,
max_=10,
range_text = ['球队数量(个)颜色区间:', ''], #分区间
is_piecewise=True, #定义图例为分段型,默认为连续的图例
pos_top= "middle", #分段位置大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
pos_left="left",
orient="vertical",
split_number=10 #分成10个区间
)
)
.add("球队数量",list,maptype="china")
.render("Map2.html")
)
5.中国足球中长期发展规划词云图
代码:
import re # 正则表达式库
import collections # 词频统计库
import numpy as np # numpy数据处理库
import jieba # 结巴分词
import wordcloud # 词云展示库
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt # 图像展示库
# 读取文件
fn = open('足改.txt','r',encoding='utf-8') # 打开文件
string_data = fn.read() # 读出整个文件
fn.close() # 关闭文件
# 文本预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"') # 定义正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
# 文本分词
seg_list_exact = jieba.cut(string_data, cut_all = False) # 精确模式分词
object_list = []大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
remove_words = [u'的', u',',u'和', u'是', u'随着', u'对于', u'对',u'等',u'能',u'都',u'。',u' ',u'、',u'中',u'在',u'了',
u'通常',u'如果',u'我们',u'需要'] # 自定义去除词库
for word in seg_list_exact: # 循环读出每个分词
if word not in remove_words: # 如果不在去除词库中
object_list.append(word) # 分词追加到列表
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
word_counts_top10 = word_counts.most_common(10) # 获取前10最高频的词
print (word_counts_top10) # 输出检查
word_counts_top10 = str(word_counts_top10)
# 词频展示
mask = np.array(Image.open('3.jpeg')) # 定义词频背景
wc = wordcloud.WordCloud(
font_path='simfang.ttf', # 设置字体格式
mask=mask, # 设置背景图
max_words=200, # 最多显示词数
max_font_size=150, # 字体最大值
background_color='white',
width=800, height=600,
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
wc.to_file('wordcloud.png')
四、总结
中国有发展足球的潜力、也拥有发展中国足球的必要性。发展中国足球,可以强健国民体魄和奋斗的精神,在这个“宅时代”提升中国人特别是中国青年的体质,中国足球的发展也可以成为新的经济增长点,可以排解城市人口情绪压力、也可以通过足球基层组织的发展来增强社会的凝聚力。少年强则国强,现状的中小学生和中国青年,过分强调他们的文化学习,他们的劳动锻炼和体育锻炼又非常的不足。参与到足球运动中来,可以强健中国青少年的体魄,锻炼他们的精神,从足球运动中他们可以更好地认识自己和社会。我相信中国一定能够搞好足球。因为中国有着非常高的人口素质、有着世界第一的球迷人口、有着最让全世界眼馋的几十年的高速经济发展背景、有着强有力的国家治理体系。
长按二维码关注
如有任何问题
您可以发送邮件至
dataintellagr@126.com
或关注微博/知乎/微信后台留言
我们期待您的提问!
微博:数据智农
知乎:数据智农
邮箱:dataintellagr@126.com
制作:邱洪洋大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!

